Diving into Attention Models
Attention as a toolkit
How did attention start?
One of the earliest neural approach to machine translation used the sequence2sequence architecture. The input sentence would pass through the model encoder, to be decoded to the target language at the decoder. This presented the bottleneck problem because of input compression. All the context from original language was squeezed into a small vector.The authors of Attention suggested that this was loosing all important context from the input sentence , when translating to the target language. Hence they modelled an attention module which could attend to particular points of input, as and when the need came.
General Attention
General attention as proposed by “Vaswani et al”, gives a general formulation for attention modules:
$ \large Q= W_Q * Query $
$ \large K= W_K * Keys $
$ \large V= W_V * Value $
Then you can do a product between Query and Key values , to get:
$ \Large Z= \frac {(Q.K^T)}{\sqrt{dim_k}} $
And then a Softmax, to get, what we can refer to as score, or alignment values.
$\large S= Softmax (Z)$
A simple way to visualize what the model does can be this :
Imagine that you have 100 books in the libary. As a reader, you want to read books which match your tastes and interests. In this scenario you could device an attention model approach, where for your $Query$ (your reading interest), you want to find out ranking of the different $Values, Keys $ (books in the library).
These attention scores, would reflect the models “alignment” of your interests with the books available. Do remember that the dimension of your attention scores will ultimately match the dimensions of your original set of $Values / Keys$ (number books for this examples).
If you feel that your requirement of model capacity is lesser than this, you can try to maybe remove the matrix $W_V$, or maybe remove the Softmax.
Also the authors introduced the idea of “Multi-Head Attention”, which basically means, you have multiple sets of the attention weights values, $W_Q, W_K, W_V $, to learn the undlerying function. The belief behind this, is that since you have randomly intialized all your weight matrices, if you work with multiple such weight matrices, they will learn (gradient descent), towards different useful direction. And your model would be able to capture more intricate details.
Of course language learning, is a very complex task. One pronoun could be relating to a subject, a verb, and its relation to another probable subject . There are multiple word, one single input/word, could be depending, and hence we need to “attend” to all of these. Hence maybe why the multi-head attention makes sense. But if you think that your problem is simple enough. Maybe you are not going to need it.
For me, my use case was variable length input.
Possible reasons , for why attention could be beating RNNs in performance?
RNNs have vanishing gradient and exploding gradient problems. Which means their gradients stop propagating useful information, for the function to be learnt. As we know from gradient descent algorithm: $ \large \theta_{t} = \theta_{t-1} - \delta * learning_rate $
Sample code for Attention Module
And if you want to change towards Multi-Head attention, you can call this attention module class into this.
What is the big deal with Attention models, and transformers?
Transformers help to learn on massively parallel data, as this operation can be parallelized on GPUs. This was not possible on earlier recurrent network based systems.
Enter Longformers
I really liked reading through this paper Longfomers: The long document transformer by Beltagy et al .
This generalized approach is the Self attention way. But this is one way of formulating the problem.And it has some problems with the order of computations required, which is $O(N^2)$.

Are you aware why BERT is limited to 512 tokens?
Pre-training on BERT was done at 512 tokens, as “the memory and computational requirements of self-attention grow quadratically with sequence length, making it infeasible (or very expensive) to process long sequences on current hardware” (source: https://arxiv.org/pdf/2004.05150.pdf Beltagy et al).
The computational complexity for the Self attention approach is $O(N^2)$, which is not very conducive for doing attention on large documents with thousands of tokens.
Hence there have been different proposals for removing this complexity, and making this Self attention approach “sparser”.
Sparse attention
Why this could be useful?
Avoid computing the full quadratic attention matrix calculation

Use of a sliding attention removes so many computations. This model would attend to neighbours a token , and you can define this neighbourhood by some window size.
“Using multiple stacked layers of such windowed attention results in a large receptive field, where top layers have access to all input locations and have the capacity to build representations that incorporate information across the entire input.” So receptive field is being talked about. But why ? As.. Stacking of multiple layers will lead to different sized receptive fields, similar to what happens in stacked CNN layers.
Different dilation settings for different atention heads ?
There was mention of Global Attention in this paper: What is it supposed to mean?
Global attention can be a good way to keep track of what the Global or overall task is, while attentind locally.
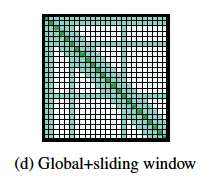
In contrast to local attention, global would maintain context for overall meaning for a document.
“the local attention is primarily used to build contextual representations, while the global attention allows Longformer to build full sequence representations for prediction.”
This paper presents their own CUDA kernel to calculate the matrix product, $(Q.K^T)$, where they mention (matrix multiplication where the output is all zero except certain diagonals; banded matrix multiplication. This operation is stated not to be present in current pytorch/tensorflow libraries. A naive implementation with loops is stated as too slow.
They train on character sequence data, as their objective is to establish whether they can tackle longer sequences.
What if you could use transfomers for Vision too !
Well that is the subject of this paper, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. Pretty dramatic name, is not it ? They do have some promising results, which showed that if enough data was thrown at transformers, they could start beating the performance of Convolutional nets in image classification tasks. And this is a big deal for the future. Fingers crossed X.
References
- Longfomers: The long document transformer Beltagy et al